
「直播回看」MetaFlow:开源的高度自动化可观测性平台
直播间的朋友们大家好,今天非常高兴能给大家带来一个好消息,云杉网络正式宣布开源MetaFlow,一个高度自动化的可观测性平台。这是云杉网络从2016年以来,商业化产品DeepFlow从云网络发展到云原生应用持续积累的结果。
MetaFlow包含了我们在可观测性建设中核心的关键技术,今天正式开源并共享给社区,为可观测性发展共同建设出一份力,同时也向世界领先的目标往前迈进一步。
今天的分享分为4个部分,第一部分从可观测性建设角度出发,总结大家在日常工作中遇到的痛点;第二部分介绍MetaFlow的软件架构、系统组成、外部的扩展能力等;第三个部分讲解MetaFlow的关键特性,包括为什么说它是高度自动化的,以及我们到底有哪些创新能力能够称得上是世界级的能力;第四部分来畅聊MetaFlow的诞生、开源、未来和贡献。
一、可观测性建设的痛点
1. 开发者一半时间去哪里了?
可观测性建设从去年开始在国内非常的火热,大家谈的越来越多。随着云原生、微服务的发展落地,可观测性建设逐渐成为了一个必不可少的工程手段。
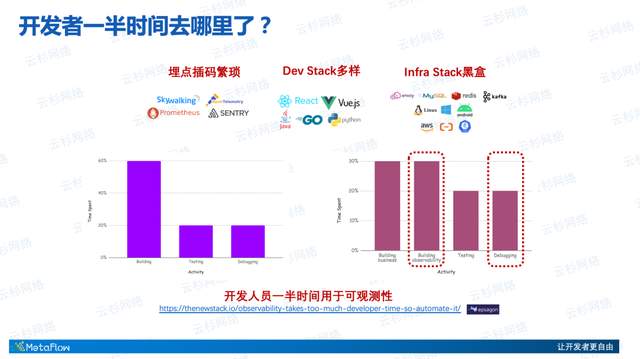
我们认为应用开发团队花了一半的时间用于可观测性的建设。这张图里面可以看到,开发者通常需要去思考建设可观测性的方方面面:如何在不同的Dev Stack和Infra Stack中埋点、如何插码、如何传递追踪上下文、如何生成指标/追踪/日志数据并进行关联,等等,需要考虑的问题太多太杂。
在业务流的整个链条过程中,从RUM到Service、到Serverless、到DB,会遇到Dev Stack的多样性,包括前端框架和后端开发语言的多样性;以及也会遇到Infra Stack的多样性和黑盒问题。开发者直接面对的是自己负责的微服务,可以在自己的代码里面做埋点、插码、可观测性建设。但是当遇到Infra组件的时候就无能为力了,这里面包括网络的四七层网关,存储的数据库、消息队列,计算的Linux、Windows以及现在一些loT设备(比如智能汽车)上运行的Android操作系统。除此之外,应用运行的基础设施形态也非常丰富,包括公有云、国内更多的有专有云、K8s容器、Serverless等。
这个链接:https://thenewstack.io/observability-takes-too-much-developer-time-so-automate-it/ 就是刚才提到的‘一半时间用于可观测性建设’的一个佐证,这是Epsagon做的一个调研。里面可以看到开发者有30%的时间直接在建设可观测性,去埋点、去插码生成Metrics、Tracing、Logging数据。除此之外开发者还有高达20%的时间在做Debug,而这些Debug之所以耗费了这么多时间,通常大部分是因为可观测性建设的欠缺导致。因此,实际上开发者一半的时间投入在了可观测性建设上
2. 建设可观测性平台难
另外一个方面,就是可观测性平台本身的建设非常困难,有很多技术挑战。

比如排名第一的时序数据库InfluxDB会在文档里面告诉使用者怎样去消除Tag的高基数(High Cardinality)问题。要想实现可观测性,就需要去观察软件内部的状态,不能将开发者辛勤埋点、插码标记的标签剥离掉。中间图片是一篇腾讯云监控的文章,里面分析了链路追踪很多采样的办法,这是在猖獗的数据之下,大家无可奈何选择的一些做法。左下角的图片是字节跳动在构建可观测性SaaS平台的一个JD。从这些都可以看出建设可观测性平台其实是非常困难的。
刚才我们讲到Trace采样,分布式链路追踪的鼻祖—— Google Dapper论文的作者Ben Sigelman创立了一家可观测性SaaS公司Lightstep,他们的用户分享了大量Tracing的最佳实践,其中很多用户都谈论到不希望Tracing数据有任何的采样,因为越是长尾的数据,越能反映问题,越可能发掘出更大的价值。而且这部分长尾的用户可能碰到问题以后直接就走掉了,它相比一些经常高频使用你产品的用户,受到这些低频故障的影响会更大。
二、MetaFlow的软件架构
1. MetaFlow从哪里来 —— DeepFlow
那么言入正题,接下来揭晓MetaFlow的软件架构,可能有一些新朋友第一次了解到云杉网络,实际上MetaFlow并不是我们刚刚开始开发。从2016年开始,云杉网络自研了一款云网监控产品DeepFlow,最初用于私有云环境下的云网络性能监控,得到了金融、能源、运营商等行业客户的高度认可。随着容器技术越来越多的应用到企业的IT建设中,DeepFlow也从2020年开始逐步从云网监控走向了云原生应用可观测性这一更广阔的舞台。

MetaFlow正是从DeepFlow里面诞生出来的。这是一个DeepFlow架构图,我们可以看到它面向公有云、私有云,面向于Any Dev stack、Any Infra stack,以及面向于云里面的NFV的网关。DeepFlow采集器能实现零侵扰的数据采集,数据节点能实现高性能的数据存储和查询,能面向网络和应用提供全栈、全链路的性能指标和追踪数据,并且能够和外部SkyWalking、Elasticsearch等可观测性系统做数据关联。
这是MetaFlow诞生的土壤。DeepFlow目前已经发展到v6版本了,还在持续、高速的迭代中。MetaFlow作为DeepFlow的核心,作为我们最顶尖技术的集合,我们希望将它开源,使得它能够走向世界,能够获得更大范围的使用,能够带给全世界范围内的开发者更好的可观测性体验,进而借助开源社区也能够让自身获得更大的迭代和发展。
2. MetaFlow的使命和愿景
MetaFlow的GitHub地址:https://github.com/metaflowys/metaflow
这段时间我们还在整理代码,预计6月底会将全部代码推到GitHub中,现在里面有一个README文件,以及同步到
MetaFlow官网:https://deepflow.yunshan.net/metaflow.html
的文档。文档中阐述了MetaFlow的设计理念、关键特性、解决的问题、软件架构等,供大家学习了解。
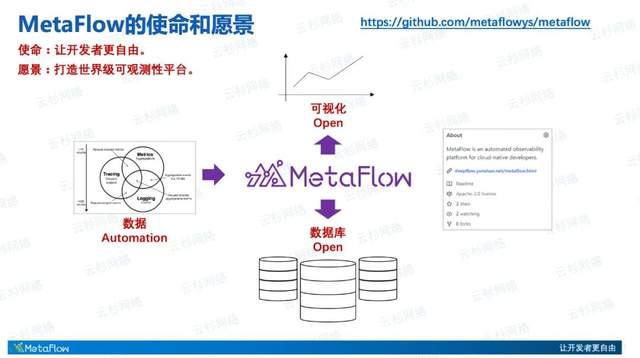
我们为什么考虑开源MetaFlow?我们希望通过MetaFlow带给开发者自由,能够自由选择开发语言和框架,能够将花费在可观测性建设上的一半时间拿回来。我们希望将MetaFlow打造成一个世界级的可观测性平台,面向全球的云原生应用开发者,成为他们建设可观测性的首选。
这里展现了MetaFlow在可观测性建设中所处的位置,它面向 Metrics、Tracing、Logging各种可观测性的数据源,并且创新的使用eBPF、OpenTelemetry等新技术极大提升数据采集的自动化程度。除此之外,MetaFlow有一个开放的数据库接口,可以通过组合或替换来选择最适合的数据库存储观测数据。向上MetaFlow提供一个统一的SQL接口,使得开发者能快速将MetaFlow融入到已有的可观测性平台中。
作为一个开源组件,开放的数据源接口、开放的数据库接口、开放的可视化接口,以及我们所选择的开放的Apache 2.0 License,我们希望将MetaFlow完全开放给世界,接受全世界范围的使用和挑战,接受全世界开发者的前进推动力
3. MetaFlow的定位
下面来介绍MetaFlow的定位,在之前的直播中我们也提到过,开源的可观测性方案非常多,比如 OpenTelemetry、 SkyWalking、Elasticsearch、Prometheus等,每一种可观测性解决方案都有他最擅长的地方,都有他聚焦的地方。MetaFlow聚焦在哪里呢?它以Tracing数据(Request-scoped数据)为核心。MetaFlow名称中的Meta是我们对自动化的追求,以及对给开发者带来自由的使命;名称中的Flow即Request,包括应用层面的HTTP、Dubbo、MySQL、Redis等Request,以及网络层面的TCP、UDP的Request。从应用和网络的Flow中,我们能采集得到Raw request event,能够聚合提取得到Request-scoped metrics,能够通过自动关联构建分布式Request的Trace火焰图。
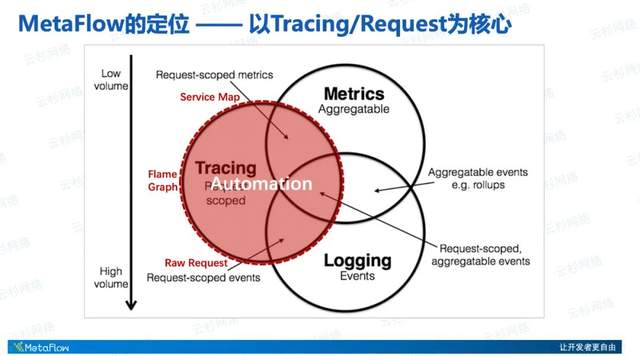
但MetaFlow是开放的,它能够将任意的Metrics、Tracing、Logging数据都集成进来,并且这不是一个简单的集成,它会将所有的数据进行统一的增强处理,使得我们能关联各种不同数据源的观测数据,彻底消除数据孤岛,同时也赋予数据更强大的切分下钻能力,让数据得以流动。

4. MetaFlow的软件架构

刚才讲到我们的定位、发展,现在揭开面纱MetaFlow到底长什么样,大家可以看到MetaFlow的架构其实非常简单,它简单到只有一个Agent和一个Server,分别是数据采集组件和数据存储查询组件。这样简单的两个组件能做到哪些事情,我们分别来看一下。
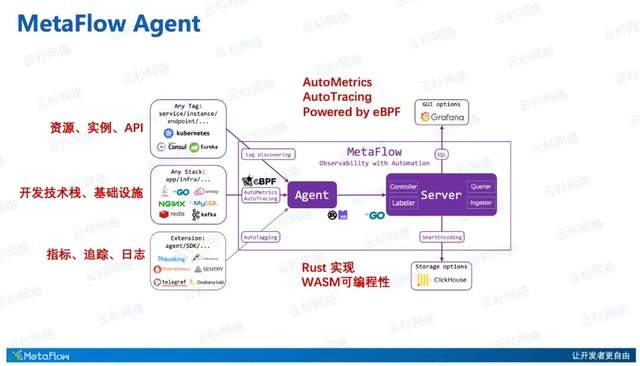
MetaFlow Agent有可能是可观测性领域第一个使用Rust来实现的高性能、内存安全Agent,同时它也支持通过WebAssembly技术提供灵活的可编程能力。它的核心能力得益于eBPF这项创新的技术,我们创新的去使用eBPF实现了对任意开发技术栈、任意基础设施的全自动应用性能指标数据采集(AutoMetrics),以及自动化的分布式链路追踪(AutoTracing),这两项是MetaFlow Agent独有的能力,能极大降低开发者建设可观测性的工作量。
除了通过eBPF来采集观测数据以外,它还通过和K8s、服务注册中心的信息同步,来自动发现丰富的服务、实例、API属性。这些属性信息用于MetaFlow Server进行自动化的标签注入,等会我们进一步阐述。
除此之外,MetaFlow Agent支持集成广泛的开源Agent和SDK的观测数据。MetaFlow拒绝造轮子,因此对于像Telegraf、Prometheus、SkyWalking、OpenTelemetry、Sentry、Loki等开源社区优秀的可观测性数据源,MetaFlow都能集成进来。而MetaFlow Server的一一系列领先能力,又会让大家感受到将其他数据源集成到MetaFlow中的巨大收益,相信能带给大家全新的体验。

那么我们就来看一下 MetaFlow Server到底有哪些能力。Server进程包含了4个内部模块:Controller面向采集器Agent的管理,能纳管多资源池的10万量级的Agent;Labeler面向标签数据的自动注入,提供AutoTagging的能力;Querier面向数据查询,提供统一的SQL接口;Ingester面向数据存储,提供插件化的、可替换可组合的数据库接口。一个Server进程囊括4个模块,是因为我们希望将复杂度隐藏在MetaFlow内部,展现给使用者的是一个干净的使用界面。它支持水平扩展,而且完全不依赖外部的消息队列或负载均衡,就能够去实现对多个Region、多个资源池中Agent的负载均摊。
MetaFlow Server也有两个非常核心的技术,AutoTagging和SmartEncoding。通过AutoTagging我们能为Agent采集到的所有观测数据自动注入统一的资源、实例和API标签,使得我们能够消除不同数据类型之间的隔阂,增强所有数据的关联、切分、下钻能力。SmartEncoding是我们非常创新的一个高性能的标签编码机制,通过这个机制,我们能将标签注入的存储性能提升10倍,这在我们的实际生产环境中已经进行了广泛的验证。
在存储方面,作为第一个MetaFlow的开源版本,我们默认提供ClickHouse的选项,开发者也可以组合、扩展更多的数据库选项。因为MetaFlow Agent采集了各种类型的可观测数据,不同类型的数据应该由不同的擅长的数据库来存储。数据库这个领域最近非常卷,经常看到会有一些新的、高性能的数据库出现。目前ClickHouse的性能傲视群雄,但相信接下来会有更优秀的一些数据库,更适合特定类型的可观测性数据的存储和查询。
MetaFlow向上提供统一的SQL查询接口,用于查询底层任何数据库中任何类型的可观测性数据。我们没有去选择自创一种查询语言,也没有去选择使用一种适合某种特定数据的QL方言(例如PromQL)。MetaFlow作为一个可观测性平台,希望为开发者提供最标准的、最易于使用的查询接口。我们基于SQL开发了MetaFlow的Grafana DataSource和交互式的查询条件编辑器。开发者也可基于SQL快速将MetaFlow融入到自己的可观测性平台中,同时也可基于SQL开发自己喜欢的QL方言。
三、MetaFlow关键特性
从刚才的软件架构介绍,我们对MetaFlow已经有了基本了解,知道它是什么,它能做什么,那么接下来给大家介绍一些干货,就是MetaFlow的关键特性。我们在这里总结了MetaFlow的六个关键特性,前面三个是面向使用者的:全栈、全链路、高性能。我介绍完之后,直播间的朋友们可以评价一下MetaFlow的“全”是不是真的,是不是世界级的。后面三个特性是面向维护者的:可编程、易扩展、易维护。

1. 全栈 AutoMetrics & AutoTagging
先来看一下MetaFlow的全栈能力,首先我们用一张图来表达云原生应用运行环境的复杂性。一方面,开发者使用的Dev Stack之多,包括各种前端程序的框架、后端程序的语言,而且一直在快速的迭代发展。另一方面,应用程序运行的Infra环境非常复杂,应用以进程形态运行在Pod中,可能会有Sidecar为他提供服务,而Pod可能在虚拟机中,除此之外两个宿主机之间可能还会有各种复杂的四七层网关。MetaFlow首先能做到的能力就是利用eBPF和BPF技术,实现真正的Any Stack的应用性能指标数据采集,即它的AutoMetrics能力。
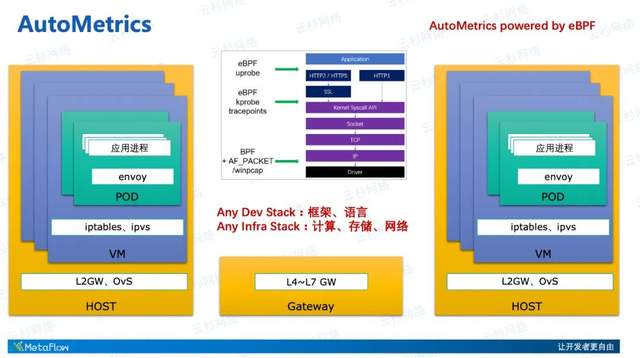
大家可以看到,MetaFlow完整的使用了eBPF的kprobe、uprobe、tracepoints能力,也完整的使用了eBPF的前身——已经有三十年历史的BPF的能力,与AF_PACKET、Winpcap等机制结合,实现面向任何操作系统、任意内核版本的全自动的数据采集。也就是说,不管一个调用是发生在Application这一侧的客户端或服务端,不管是一个加密之后的HTTPS调用、编码之后的HTTP2调用,还是普通明文的HTTP、Dubbo、MySQL、Redis调用,都能自动的获取到它的每一个调用的事件详情及RED(Request、Error、Delay)性能指标。
不管这个调用流经的是Pod的虚拟网卡、VM的虚拟网卡、宿主机的物理网卡,还是中间的NFV虚拟网关,或者七层API网关,只要有MetaFlow Agent部署到的地方,都可以通过eBPF/BPF技术从内核中获取到调用数据,并生成应用层面的RED指标、网络层面的吞吐、时延、异常、重传等指标。这样的指标采集是完全自动化的,它不需要我们的开发者手动做任何的埋点或插码,所有这些能力,通过部署MetaFlow Agent即可自动获取到。
同时我们看到了这些观测数据来自系统中不同的层面,有来自应用程序函数的(uprobe)、有来自系统调用函数的(kprobe),也有来自虚拟机、宿主机、中间网关网卡流量的(BPF)。那么怎样把这些数据关联起来,使得我们能完整的观测一个调用的全栈性能?这就依赖于MetaFlow的AutoTagging技术了。MetaFlow Agent通过同步K8s、服务注册中心的大量的资源、服务、API属性信息,然后由Server进程汇总并统一插入到所有的可观测性数据上,使得我们能够无缝的、在所有数据之间关联切换,呈现应用调用的全栈性能。
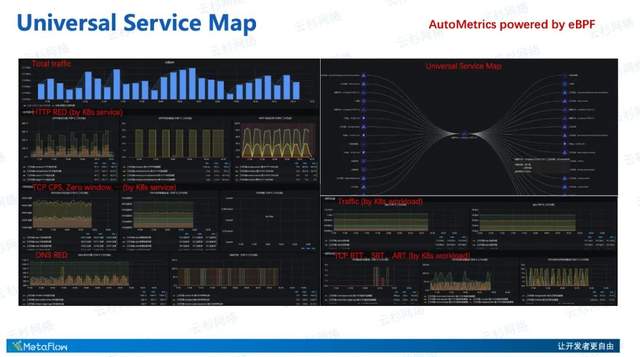
对于AutoMetrics机制获取到的指标数据,我们基于SQL接口开发了相应的Grafana DataSource和Pannel,这张图里展示的是我们通过Grafana呈现的从应用到网络,包括HTTP、TCP、DNS协议、各个K8s工作负载和微服务的性能指标,以及K8s服务之间的应用调用关系——Universal Service Map。
2. 全链路 AutoTracing
接下来介绍MetaFlow的全链路追踪能力。我们现在去搜索引擎中搜索 eBPF Tracing,会呈现大量的结果,但这些其实与我们在可观测性建设中通常所谈论的分布式链路追踪没有关系。接下来的介绍相信能带给大家更大的震撼,是我们基于eBPF技术非常领先的创新,实现自动化的分布式链路追踪能力AutoTracing。
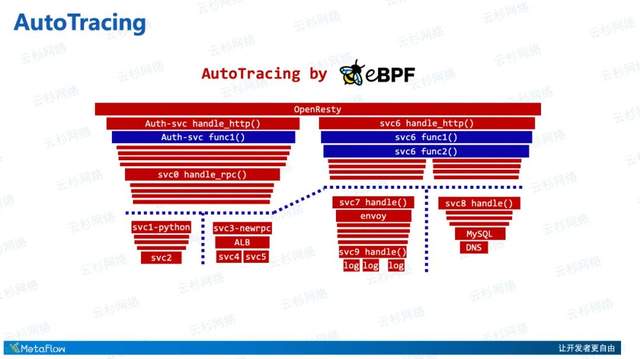
我们现在所看到的这样一张残缺的、有盲点的追踪图,是一组用Java和Python构建的微服务。右上角是它的一部分调用拓扑,它的右侧是完成业务的Java微服务,左侧是完成权限验证的Python微服务。实际上他们应该是一个完整的Trace,最顶端使用Nginx等API网关将两组服务连接起来,但目前我们所能使用的手动插码技术可能由于各种各样的原因无法追踪完整,缺少Infra层面的Span,以及可能由于不同服务团队使用不同的Tracer使得火焰图无法展现完整,亦或是缺乏对某些语言、某些RPC框架的插码导致追踪断裂。这些盲点会使得我们排查问题的时候经常得不到答案,乃至导致团队之间的相互推诿
MetaFlow能带给分布式追踪什么样的改变呢?首先我们看看MetaFlow单纯使用eBPF的震撼效果。这是我们自动追踪能力的一个示意图,依靠eBPF的能力,依靠MetaFlow的创新使用,我们能自动化的、高度完整的展示出微服务调用链。在这张火焰图中,红色的部分是eBPF已经点亮的地方,eBPF追踪的是每个Request相关的TCP/UDP通信函数,通过挂载到这些系统调用函数中实现自动追踪。
当然大家还可以看到里面也有一部分蓝色的地方没有点亮,包括一些中间过程函数,或者一些异步调用导致的追踪断裂,在发生一些异步调用的时候,这张Tracing图可能会被切分成一些孤立的小岛。这些缺陷也是未来我们工作的方向,使得自动追踪能更加完整,幸运的是我们现在已经有了非常好的思路,有望将AutoTracing的能力延展到异步调用场景、协程调度场景中。MetaFlow带给大家的是一个全新的创新能力,不需要做任何的埋点、插码的AutoTracing机制。
但是任何时候我们不用拿着一个锤子去找钉子,放眼世界,除了eBPF以外,其实社区已经有了一个非常好的、有望从标准化角度实现自动化的追踪机制——OpenTelemetry,它的发展也非常迅猛。秉承着拥抱社区的理念,MetaFlow会将数据进行充分的集成和自动化的关联,再呈现给大家时,就是下面这些星星之火构成的燎原之势了。通过eBPF和OpenTelemetry,构成了我们一个完整的、自动追踪出来的分布式调用链。
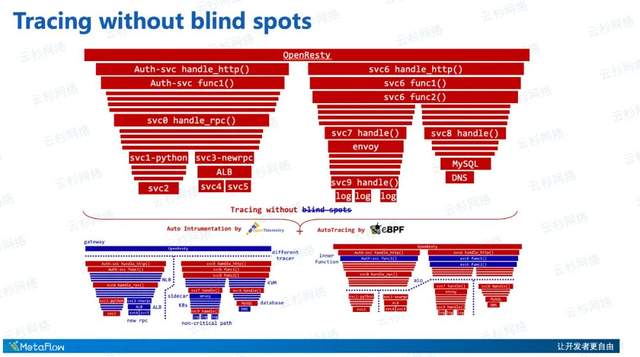
我们通过eBPF和OTel的结合,可以解决哪些问题呢?对于eBPF来讲,它解决OpenResty Gateway、MySQL Database无法插码无法追踪的问题,解决KVM vSwitch、K8s iptable/ipvs、Service Mesh Sidecar、ALB、NLB等等无法追踪的问题,所有的这些路径我们都可以去通过eBPF的能力实现自动追踪。
eBPF也有助于发现我们一些预期之外的路径,比如MySQL在做SQL语句执行的时候由于DNS查询导致的高时延,或者是微服务在响应API过程中频繁写日志导致的搞试验,都是我们通过eBPF能够补充进来的。对于OTel来讲,也能向eBPF的AutoTracing火焰图中补充非常有价值的Inner Function Span,以及修复由于异步调用、协程调度等原因造成的追踪断裂,最终让我们拿到一个高度完整的、没有任何盲点的全链路追踪图。Tracing without blind spots也是MetaFlow全链路追踪的信仰。
当我们的观测性没有任何盲点的时候,我们就能回答一些以前我们完全回答不了的问题。比如业务开发人员抱怨SQL慢,从Java进程中输出的Span看到的时延是3秒,但是DBA跑到 MySQL的日志里面找了很久就是找不到慢日志,这个事怎么说?通过MetaFlow的全链路追踪能力,我们可以去精确定位到根因,能直接告知到底是Java微服务和MySQL哪一方、以及中间链路的哪一跳出现了问题。这样的长尾事件可能是低频发生的,会经常发生在我们日常的排障工作中,变成整个业务系统的隐患,造成相应的业务的损失,最终导致客户的流失。
3. 高性能 SmartEncoding
作为一个技术人员来讲,不得不隆重介绍一下MetaFlow的高性能。首先,MetaFlow Agent或许是第一个用Rust实现的采集器。在可观测性领域,我们可以看到像Telegraf、Prometheus等基本都使用Golang实现,MetaFlow为什么选择Rust呢?这其实和他所处理的数据量有关,诸如Telegraf等一般采集频率是一分钟一次,或者说十秒一次。
但 MetaFlow采集的数据是精细到毫秒、微秒甚至到纳秒的,因为他要去采集每一个请求,每一个网络上的TCP会话,因此我们非常关注Agent的资源消耗。
DeepFlow从2016年开始用Golang开发了第一代采集器Trident,我们基于原生的Golang数据结构做了大量的优化,例如我们开发了自己的高性能hmap、高性能内存池hpool,这些现在也已经开源了,大家可以上GitHub上查看。这些非常细节的优化使得我们在Golang语言下积累了诸多10x性能提升点。但我们并没有满足这样的性能表现,从去年开始我们决定将采集器升级到Rust版本。使用Rust可以解决Golang中高频数据处理带来的GC问题、内存消耗问题。经过这样的升级使得MetaFlow Agent可以运行在更加广阔的环境中,特别是资源受限的IoT环境中。
左图是我们在一个极限环境下的压测,可以看到MetaFlow对于CPU的影响,通过eBPF获取所有的应用调用数据,对 CPU的影响增加只增加了3%(注意测试的是一个非常简单的Hello World的Nginx web page)。通过从Golang到Rust的升级重构,获得了非常显著的性能提升,同时也打开了更多的应用场景的大门。右图展示了MetaFlow Agent在智能汽车的loT环境中的更广阔的使用,这是我们商业产品DeepFlow的一个车联网解决方案。
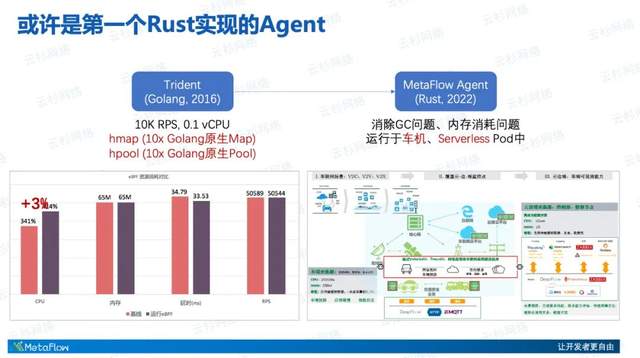
第二方面的高性能体现在Server端,这里有一个简单的数据,就是我们的资源开销大概相当于业务开销的1%,这是在大量的商业客户生产环境下验证的。捎带提一下MetaFlow Server是用Golang来实现的,由于我们刚才介绍的在Golang Agent上积累下来的众多黑科技优化,整体的性能表现非常好。在100万Request每秒的实际生产环境中,我们整个资源开销非常低,不到业务的1%的消耗。
第三个方面是我们的 SmartEncoding智能标签编码技术。MetaFlow会为所有观测数据自动注入大量的Tag,比如在容器环境中,从客户端去访问服务端这样的双端数据,可能要注入上百个维度的标签,这些标签有可能是非常长的字符串,给我们的后端存储造成了非常大的压力。
MetaFlow创新的使用SmartEncoding机制,在Agent上独立采集标签和观测数据,同步到Server端后对标签进行独立的整形编码,并将整形编码注入到观测数据中存储下来。创新的SmartEncoding机制可以使得整个标签的注入开销降低10倍。另外由于存储的标签都是Int编码之后的,有助于降低查询过程中的数据检索量,也能显著提升查询性能。
而对于一些衍生的Tag则完全没必要存储在数据库中,MetaFlow Server通过SQL接口抽象出来底层的一个大宽表。比如在底层我们存储了40个标签,通过Server的抽象,把它延展成100个标签的虚拟大宽表。上层应用在虚拟大宽表之上进行查询,完全感受不到标签是否存储在数据中、是以Int还是String的形式存储
4. 可编程、易扩展、易维护
最后介绍的是MetaFlow的另外3个重要特性。首先是基于WebAssembly的可编程能力。它在我们Milestone里面,即将发布的第一个开源的版本里暂时不具备这样能力,在此提出来是因为这是未来我们明确的一个迭代方向。我们希望通过可编程能力的开放,可以让使用者解决更广阔的的问题,比如对私有协议的解析,以及比如在MetaFlow之上开发面向特定业务场景(例如5GC、金融交易、车联网等)的监控能力。通过WebAssembly其实相当于给MetaFlow Agent提供了一个类似于JVM虚拟机的能力。
易扩展首先是数据源的可扩展。其实刚才也讲到我们的Agent能够吸纳很多的数据,那么为什么开发者愿意将这些数据输出给MetaFlow呢?因为MetaFlow有着AutoTracing的自动化和SmartEncoding的高性能,使得我们能高效的接纳不同数据源,并且连接它们,消除数据孤岛,赋予他们更强大的下钻切分能力。给开发者带来完整可观测性的同时,也避免了需要在代码中辛辛苦苦的一行行手动注入标签数据。
易扩展其次体现在数据存储和查询上。刚才也提到我们的数据库插件模式,底下不管是什么样的数据库,向上暴露的都是统一的SQL查询能力。我们很可能在一个大的组织里面已经有了自己的可观测数据库,已经有了自己的Dashboard,通过SQL的能力,可以对接到MetaFlow。也可以基于SQL实现自己的方言,同时MetaFlow在未来的规划中也计划基于SQL实现PromQL等流行的方言,更加无缝的帮助大家从已有的可观测性技术栈迁移到MetaFlow上。
最后讲易于维护,实际上体现在MetaFlow的架构上。我们将很多复杂的机制隐藏在进程的内部,暴露出来的只有Agent和Server,而且 Server有很好的 Client-side load balancing机制,使得它可以自动调度Agent与Server的负载分摊。并且MetaFlow的Server可以去管理多个K8s集群、虚拟机资源池、裸机资源池中的Agent,而且整个Server的能力支持做多区域的扩展。
四、O11Y的未来
今天的直播已经接近尾声了,下面用几张简单的PPT畅想一下可观测性未来。
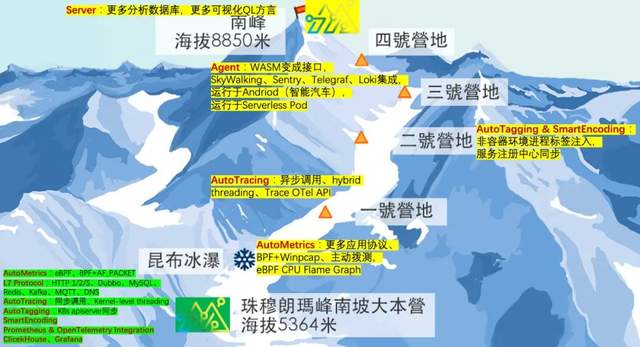
首先介绍一下MetaFlow未来的规划,我们就像攀登珠峰一样,MetaFlow目前不是从海平面开始攀登的,它站在DeepFlow六年的积累之上,已经有了非常酷的AutoMetrics,AutoTracing、AutoTagging、SmartEncoding等创新能力,这些能力会随着我们下个月的第一个版本出现在GitHub上,提供大家直接下载使用。
第一个版本的能力包括:1)基于eBPF和BPF的AutoMetrics能力,并支持大量应用层协议;2)基于eBPF的AutoTracing能力,帮助大家解决同步调用模型和Kernel-level threading语言中的自动追踪问题,稍微说明一下所谓Kernel-level thread就是我们一般见到的1:1的线程模型,像Java、 Python、 Node.js都属于这一类;3)通过同步K8s的AutoTagging能力;4)高性能的SmartEncoding机制;5)和Prometheus、OpenTelemetry数据的集成能力;6)默认数据库ClicekHouse和默认GUI Grafana。这些都是我们第一个版本的起点,就像攀登珠峰的大本营。
在这里我们更希望给大家介绍的是未来珠峰的攀登,现在只到一半,我们未来还有很多工作。比如我们的AutoMetrics,我们会支持更多的应用协议解析,我们会支持Windows环境的运行,会支持主动拨测,会支持通过eBPF获取CPU火焰图。比如我们的AutoTracing机制,除了支持同步调用和Kernel-level thread模型以外,我们正在探索异步调用和协程调度场景下的自动追踪能力。
我们也在思考更多的创新能力,比如说我们是不是可以利用OTel的标准API,完全不去做Tracer的实现,而是在eBPF里面通过挂接Tracer的标准API函数实现追踪能力的解耦,这个特性想想也非常酷。
再比如AutoTagging、SmartEncoding也会继续去迭代,我们在非容器环境下,进程信息的标注能力,服务注册中心的同步能力。以及Agent的 WebAssembly的编程接口, SkyWalking、Sentry、Telegraf、Loki的集成。以及我们现在正在做的将Agent运行于Android操作系统(智能汽车)中,运行在Serverless Pod中,以及我们的Server可以去适配更多的分析数据库,支持更多的QL方言,这些事情都是非常激动人心的。
我们可以想象一步一步的将MetaFlow迭代,它必将是一个世界级的可观测性平台,能够帮助开发者构建一个非常自动化的可观测性平台,彻底释放开发者的生产力,带来自由。
讲了这么多,不知道大家有没有意犹未尽的感觉,在这短短1个小时的时间里,我没有办法将MetaFlow的能力细致入微的进行展现。后续我们还会有一系列的活动,将MetaFlow一步一步介绍给大家,就在6月的QCon 2022开发者大会上,我也非常荣幸能够和BAT同台竞技,带给大家云杉网络在eBPF方面的实践和创新,深度揭秘我们怎么去做到AutoMetrics,AutoTracing,希望大家可以多多关注。

Related Posts

「直播回看」DeepFlow——开启高度自动化的可观测性新时代
我们相信DeepFlow 是送给新时代开发人员、运维人员的一份礼物。我们希望开发人员能有更多的时间聚焦在业务上,将可观测性更多的交给自动化的 DeepFlow,让自己的代码更清晰整洁。
Read More
「直播回看」高清云网可观测之全链路追踪实战
“云原生可观测性分享会”第七期《高清云网可观测之全链路追踪实战》由云杉网络 高级产品经理 李倩分享,针对云网络的全链路追踪问题,用「实战」带领大家一步一步破解“网络谜案”。
Read More
SDN in China
2022年5月17日
技术探讨, 核心技术