使用 DeepFlow 开启 DNS 可观测性案例
接下来,让我们结合实际案例,来体验一下 DNS Dashboard 给我们带来的高效分析能力。
案例1 – 无效内部域名解析
现象:
我们的集群里的应用规模不大,理论上 DNS 请求不会太多,但我们打开 DNS Dashboard 后,发现有大量 DNS 查询请求,且有访问异常:
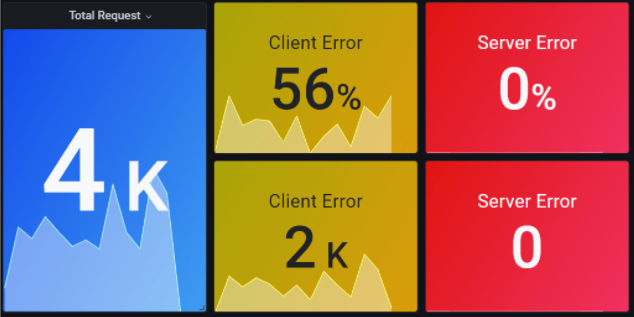
其中有较多 DNS 客户端异常,响应码为 0x3,错误描述是:Non-Existent Domain,意味着应用访问了不存在的域名。(更多的异常定义可见 DeepFlow-数据库字段定义[4])
我们通过异常排序,查看访问无效 Top10 域名,发现大量 DNS 请求后缀包含了 cluster.local,而这是 k8s 自动填充的搜索域:
原因分析:
我们结合 k8s 的 DNS 原理来分析问题原因。首先,一个典型的 k8s Pod 中 resolv.conf 文件的内容如下:
这里有三个配置,search 是域名检索的搜索域,nameserver 是集群内的 DNS 服务地址,options 是自定义选项,其中 ndots=5,意味着当一个域名中包含.的数量小于 5 时,会优先解析为内部域名,并按照 search 的顺序依次添加搜索域后缀来检索,如果它依然无法被解析,才会把这个域名当作外部域名来解析。
那为什么 k8s 的 ndots 默认配置是 5 呢?Issue#33554[5] 也做出了解释,简单来说:
1、同命名空间下,形如 $service 的域名要被优先解析为内部域名,所以 ndots>=1,并在搜索域 zone 下搜索。
2、跨命名空间下,形如 $service.$namespace 的域名要被优先解析为内部域名,所以 ndots>=2,并在搜索域 svc.$zone 下搜索。
3、访问非 Service Name 时,形如 $name.$namespace.svc 的域名要被优先解析为内部域名,所以 ndots>=3,并在搜索域 $zone 下搜索。
4、对于 StatefulSet 类型的应用,由于需要支持形如 $name-0.service.$namespace.svc 的域名内部解析,所以 ndots>=4。
5、对于形如 $port.$proto.$service.$namespace.svc 的 SRV Record 要被优先解析为内部域名,所以 ndots>=5。
综上,k8s 的 resolv.conf 中 ndots 默认值是 5 。但这符合我们的使用场景吗?我们要访问的域名是一个.小于 5 的外部域名,但它被解析为内部域名,并尝试通过 url.default.svc.cluster.local / url.svc.cluster.local / url.cluster.local的顺序来解析,最后才去访问 url 本身,所以产生了大量的异常记录。
修复建议:
要解决这个问题,有几个可选的方案:
1、k8s 文档中 Pod DNS 配置[6]一节,只需要修改 Pod 的 DNS 策略,定义 ndots=2,这样就可以优先将域名解析为外部域名,弊端在于这样反而会使得内部域名的解析变慢。
2、把访问的外部域名修改为 FQDN,比如我们要访问的是 vpc.tencentcloudapi.com,修改为 vpc.tencentcloudapi.com.,这样可以直接访问域名,不会依次检索搜索域。
3、CoreDNS 使用 autopath 插件[7],减少搜索次数,但这依赖于 API Watch 机制,会使得 CoreDNS 增加内存消耗。
4、使用 Node LocalDNS[8],增加 DNS 解析性能,减少 CoreDNS 压力,但同样的,它需要使用内存来做 DNS 缓存查询,增加了内存消耗。
经过权衡,方案(2)对集群的侵入性和修改难度是最低的,效果也比较理想,所以我们采用方案(2)达成了目标。
案例2 – 对已失效服务的依赖
现象:
同样通过 DNS Request Log 分析,我们发现还有大量的 Non-Existent Domain 异常,且它不是访问外部域名:
原因分析:
集群里没有 zipkin 的 Service,按照上述的 k8s 的 DNS 原理分析,在访问域名的时候同样会尝试按搜索域顺序依次访问,造成了不小的 CoreDNS 压力,这说明应用的配置有错误,尝试访问无效的服务,导致冗余的开销。
修复建议:
检查代码或配置中是否还在访问失效的服务,去掉配置后恢复正常。
后续规划
我们目前在制作一批 Dashboard,包括:Nginx、MySQL/PostgreSQL、HTTP、Dubbo/gRPC、Kafka/MQTT、TCP/UDP/IP 等,希望能带来社区高度自动化、高精度的可观测性体验,期待有社区的小伙伴能加入一起。
什么是 DeepFlow
DeepFlow[9] 是一款开源的高度自动化的可观测性平台,是为云原生应用开发者建设可观测性能力而量身打造的全栈、全链路、高性能数据引擎。DeepFlow 使用 eBPF、WASM、OpenTelemetry 等新技术,创新的实现了 AutoTracing、AutoMetrics、AutoTagging、SmartEncoding 等核心机制,帮助开发者提升埋点插码的自动化水平,降低可观测性平台的运维复杂度。利用 DeepFlow 的可编程能力和开放接口,开发者可以快速将其融入到自己的可观测性技术栈中。
GitHub 地址:https://github.com/deepflowys/deepflow
云杉 世纪
2024年4月3日
云杉动态