
强者恒强:x86高性能编程笺注之循环(下)
读者须知:《强者恒强:x86高性能编程笺注》是云杉网络推出的系列技术分享,该系列文章将分享x86高性能开发方面的实践和思考。主要内容目录如下,欢迎各位业界同仁与我们讨论交流相关话题。
- 什么是性能
- 流水线
- 分支
- 循环
- 缓存
- 预取
- 大页
- 锁
- RCU
- 无锁
- SIMD指令
Loop Unrolling
循环展开是一种应用最多,流传最广泛的循环性能优化技巧。优化方式也很好理解,将多次循环的处理内容铺延到一次循环中处理,减少对迭代器值的判断和分支选择,就是循环展开。循环展开之后可以成倍减少循环的overhead,让CPU资源能更专注于循环体的处理工作,推荐在循环体指令较少的时候操作——教科书上一般都是这么说的。
理论其实都没错,但我们在这里侧重一下实践。用perf等工具去实际探究一下性能热点究竟产生在哪里,以及优化之后的效果。虽然如今硬件和软件的发展速度已经开始让一些“奇技淫巧”加速过时,但我们在乎的也只是那一点点同时摆在时间和硅基处理器面前的禁脔而已。
- 使用-O0选项编译如下循环:
loop 1:
for (i = 0; i < 100000000; i++) {
sum += array[i];
}
在我的机器上用perf stat观察一下大体情况,可以得到如下结果:
SideNotes: perf stat可以添加repeat [N]参数指定重复执行次数,显示平均结果,添加-d显示更详细结果。
Performance counter stats for ‘./loop10’:
348.773618 task-clock # 0.999 CPUs utilized
5 context-switches # 0.014 K/sec
0 cpu-migrations # 0.000 K/sec
1,203 page-faults # 0.003 M/sec
796,895,241 cycles # 2.285 GHz [83.37%]
495,310,308 stalled-cycles-frontend # 62.16% frontendcycles idle [83.37%]
44,325,164 stalled-cycles-backend # 5.56% backend cyclesidle [66.74%]
802,774,532 instructions # 1.01 insns per cycle
# 0.62 stalled cycles per insn [83.37%]
100,538,550 branches # 288.263 M/sec [83.37%]
2,014 branch-misses # 0.00% of all branches [83.18%]0.349124017 seconds time elapsed
在正常的终端显示里,perf很贴心地把62.16%的front-end stalledcycles标成了难以抗拒的斩男色。
从前面的关于流水线的介绍中我们可以得知,front-end主要负责指令的fetch和解码,并给执行核心输送指令。既然front-end stalled那么多,我们就选择perf事件来做一下测量看看具体是哪里在浪费CPU好了:
perf record -eidle-cycles-frontend ./loop10
perf report
SideNotes: objdump -S 可以打印出目标文件的汇编代码
│ push %rbp
│ mov %rsp,%rbp
│ uint64_t sum = 0;
│ movq $0x0,-0x8(%rbp) ; 初始化sum = 0
│ int i = 0;
│ movl $0x0,-0xc(%rbp) ; 初始化i = 0
│ for(; i < N; i++) {
│ ↓ jmp 2b
│ sum +=array[i];
10.64 │15: mov -0xc(%rbp),%eax ; 在%eax中写入i的值
│ cltq
│mov 0x601060(,%rax,4),%eax ; 读取array[i]的值并写入%eax
26.95 │ cltq
17.59 │ add %rax,-0x8(%rbp) ; 计算sum +=array[i]
│ uint64_t
│ loop_process()
│ {
│ uint64_t sum = 0;
│ int i = 0;
│ for(; i < N; i++) {
44.82 │ addl $0x1,-0xc(%rbp) ; i自增
│2b: cmpl $0x5f5e0ff,-0xc(%rbp) ; 判断循环条件
│ ↑ jle 15 ; 返回循环起始位置
│ sum +=array[i];
│ }
│ return sum;
│ mov -0x8(%rbp),%rax ; sum写入%rax作为返回值
│ }
│ pop %rbp
│ ← retq
在-O0的优化条件下,汇编代码比较忠实地反映了我们的逻辑意图。可以看出front-end流水线的空等发生在循环迭代器i的自增和循环条件判断附近。
当CPU发生front-end stalled的时候,意味着流水线的前端无法最大效率地给CPU的执行核心输送指令,造成执行核心工作量不饱和,IPC下降等结果。
一般来说,front-end stalled多由于分支预测失败,指令缓存读取miss或者「复杂」指令解码速度慢造成的。但很奇怪的一点是,我们可以在上面的测试结果中看到,branch-miss并不高,指令缓存miss也很少,至于解码慢,我们并没有使用任何复杂的指令,且一段micro-benchmark的代码量也很小。那么问题到底在哪呢?
这个时候,需要搜集更多的指标来帮助推断。现代CPU提供的硬件性能计数器很丰富,不仅仅限于perf list提供的那些,但若想真正去使用它们,还是需要查阅手册。
Intel提供一部叫做《Intel® 64 andIA-32 Architectures Software Developer’s Manual》的皇皇巨著,在网上可以随意下载。有兴趣的可以自己回家暗自揣摩,在这里我们只用到第3B卷第19章“PERFORMANCE MONITORING EVENTS”中的相关内容。
在这个章节中,列出了所有CPU型号所具有的全部硬件性能检测指标,以及每个指标的详细说明,这些都可以用perf观察。我用的机器是Sandy Bridge架构,所以按图索骥,我需要看一下19-8节中所罗列的指标。
在表格19-15中我们可以注意到一个叫做UOPS_ISSUED.ANY的指标,后面的描述为:
Increments each cycle the # of Uops issued bythe RAT to RS. Set Cmask = 1, Inv = 1, Any= 1to count stalled cyclesof this core.
其中RAT是指RegisterAlias Table,RS是Reservation Station,Uops则是指令解码后生产的微指令。
- RAT主要用来做register rename以充分利用CPU寄存器和并行执行资源;
- RS相当于一个队列形式的微指令执行前的调度站,当微指令的操作数准备就绪时,将最先入队的指令送到CPU的对应Port上执行
先看一下这个指标如何使用,在指标的同一行我们可以看到Event Num和UmaskValue两列,对应的数值分别为0EH和01H:
perf stat -ecpu/event=0x0e,umask=0x01/ ./loop10
Performance counter stats for ‘./loop10’:
1,004,242,933 cpu/event=0x0e,umask=0x01/
0.346507887 seconds time elapsed
结果中第二行显示的数字即是此项指标的数值。按照说明,如果将Cmask设为1,Inv设为1,我们就可以得到stalledcycles的数值:
perf stat -ecpu/event=0x0e,umask=0x01,cmask=1,inv=1/ ./loop10
Performance counter stats for ‘./loop10’:
493,982,905 cpu/event=0x0e,umask=0x01,cmask=1,inv=1/
0.346209440 seconds time elapsed
显示的结果与用perf stat统计的结果几乎一致。
SideNotes: 事实上perf就是利用这条指令读取stalled数值的,可以用more /sys/devices/cpu/events/stalled-cycles-frontend查看。
我们在表格19-15中可以发现很多能够解释Stalled cycle具体原因的指标,比如RESOURCE_STALLS.ANY:
CyclesAllocation is stalled due to Resource Related reason.
其测试结果:
491,331,063cpu/event=0xa2,umask=0x01/
与front-end stalled总数十分接近,基本可以确认是因为“Resource Related reason”导致的CPU空等。那么具体是什么Resource?这就还需要在其提供的能力中继续验证。
在RESOURCE_STALLS.ANY下面的4个指标,都是以RESOURCE_STALLS的前缀开头,直到我们发现RESOURCE_STALLS.RS的测试结果:
490,511,517 cpu/event=0xa2,umask=0x04/
至此我们可以确定front-end stalled是由“Cycles stalled due to no eligible RS entry available”引起的了。
为了解释这一原因,我们还需要回头看一下Sandy Bridge流水线架构图:
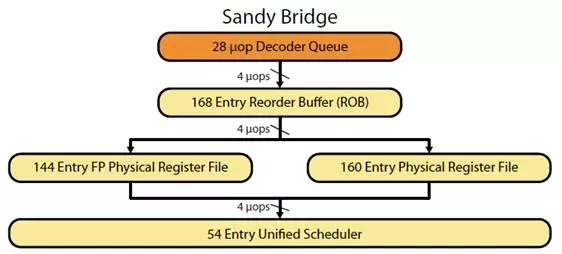 d
d
在截取出来的这一部分中,Sandy Bridge使用了Physical Register File「PRF」作为register renamer。解码好的微指令首先进入Reorder Buffer「ROB」,在这里微指令被重新排列,在保证程序执行结果的同时,提供给乱序执行核心最优的执行顺序,另外在分支预测失败的时候也可以提供快速的指令回滚等好处。
然后指令会进入图中的Physical Register File去进行register rename的操作,主要用于减少指令间的数据依赖,提高指令的并行效率。最后,进入Unified Scheduler也就是对应于我们之前提到的Reservation Station「RS」等待被执行核心执行。
简单总结一下指令在真正被执行之前的处理过程:
- Fetch
- Decode
- Reorder
- Rename
- Reservation Station
- Execute
在上图中,除了模块名称和连接关系之外,还可以注意到几个数值。
首先是Decoder Queue可以以4个微指令/周期「uops/cycle」的速率给ROB传送微指令。同理ROB到PRF,PRF到Unified Scheduler「RS」也是同样的速率。
另外就是ROB有168个条目,PRF有160个,而Unified Scheduler仅有54个。因为Unified Scheduler仅储存操作数已经准备就绪的微指令,而ROB需要储存所有解码完成的微指令,所以这样的安排是合理的。
在真正执行指令之前,Unified Scheduler「RS」需要检查指令的操作数是否已经就绪,同时CPU是否还有空闲的执行该类指令的执行单元,另外对应于不同执行单元的RS资源是固定的。
当类似的指令大量“突发”,就会造成没有空闲的RS资源的情况「比如示例循环中的情景」,指令就会在RS中堆积,RAT就无法继续再“issue”微指令给RS,造成CPU stall。
通过计算UOPS_ISSUED.ANY事件的读数与总CYCLE读数的比值,可以得出从RAT到RS的速率在1.2uops/cycle左右,小于前方4uops/cycle的速率。
当我们使用如下两段“循环展开”的代码重复以上步骤的时候,可以发现在-O0编译条件下,CPU stall的原因仍然是由于ReservationStation没有可用资源导致的。
loop 2
sum += array[i];
sum += array[i + 1];
sum += array[i + 2];
sum += array[i + 3];
}

loop 3
sum1 += array[i];
sum2 += array[i + 1];
sum3 += array[i + 2];
sum4 += array[i + 3];
}
sum = sum1 + sum2 + sum3 + sum4;
总结成一个表格-O0编译条件:
| A | B | C | D | |
| 1 | loop1 | loop2 | loop3 | |
| 2 | Cycles | 796,895,241 | 628,983,412 | 345,823,599 |
| 3 | Instructions | 802,774,532 | 650,103,585 | 651,486,504 |
| 4 | UOPS_ISSUED.ANY | 1,004,242,933 | 778,573,244 | 779,100,087 |
| 5 | Stalled-Cycles-FE | 495,310,308 | 432,527,871 | 149,837,294 |
| 6 | RESOURCE_STALLS.RS | 490,511,517 | 424,736,743 | 145,859,703 |
可以看出三个循环都是卡在RS这里,但总体占比情况不同。总体来说是按照预想的情景在提升执行性能。在-O2编译条件下,又呈现出另外一种情景:-O2编译条件。
| A | B | C | D | |
| 1 | loop1 | loop2 | loop3 | |
| 2 | Cycles | 138,924,887 | 91,329,732 | 91,021,889 |
| 3 | Instructions | 500,240,297 | 275,581,865 | 275,797,328 |
| 4 | UOPS_ISSUED.ANY | 402,660,940 | 252,385,169 | 252,402,345 |
| 5 | Stalled-Cycles-FE | 38,237,778 | 15,501,980 | 15,241,552 |
| 6 | RESOURCE_STALLS.RS | 31,899,310 | 245,321 | 600,411 |
可以看出,经过编译器的优化,三个循环均有性能的提升,但loop2和loop3的性能表现已经几乎没有区别。
同时在front-end stall相关的计数中,RS已经不是主要瓶颈。具体的原因需要探查一下汇编代码,以及综合不同的性能读数,并考虑CPU流水线的特性:「进行猜测->实验->求证->再猜测->再实验式的分析」。
这对一个爱好性能分析的人来说,可以说是最好的享受。那么这部分工作就留给感兴趣的读者。
总结
本节与其说讲述了一种循环优化方式,毋宁说是讲述了一种性能分析的方法,这种方法既可以应用于循环,也可以应用于后续的缓存和其他内容。
我知道这里还有很多很多种循环优化的方法,一般内容单薄的文档总是喜欢将它们都罗列出来以壮声势,但在这里我想我已不必再费笔墨。
作者简介
您还可以通过以下方式了解更多云杉网络的信息

关注云杉网络公众号 yunshannetworks,回复“精选”查看;

云杉网络官方网站:yunshan.net
Related Posts

大会预告|云杉网络邀你一起参加GOPS全球运维大会
第十八届 GOPS 全球运维大会将于2022年8月19日至8月20日在深圳召开。大会将为期2天,侧重方向是 DevOps、AIOps、DevSecOps、云原生、效能度量等技术领域。云杉网络受邀参会,并在“可观测性技术实践专场”分享主题演讲。
Read More
云杉网络DeepFlow帮助5G核心网和电信云构建可观测性
近几年,云原生可观测性已经成为IT领域解决业务可靠性的重要理论,“可观测性=可靠性”基本成为IT运维的共同认知。所谓云原生可观测性,简单来说就是快速有效的诊断复杂业务系统内部的运行状态。经过近十年的发展,云杉网络从SDN核心技术逐步走向网络自动化和可观测性,致力解决云原生应用诊断难的核心痛点,其中DeepFlow产品在各行各业积累了大量的实战经验,成功帮助数家企业构建多维度、一体化的可观测性平台。
Read More
SDN in China
2017年11月20日
技术干货