G行全栈云原生可观测性实践 分钟级定位业务不规律中断故障
云杉 世纪
|
2024-03-29
导读
01用户:G行、金融行业
02用户挑战:1)云网故障定位技术要求高:在云网中对每一个微小故障的定位均需要对SDN、云技术架构、容器技术架构等技术领域经验丰富的中高级工程师参与。2)云网故障定位过程繁琐:云网工程师在故障定位过程中需要从源端开始抓包、查找路由表,再到下一跳节点抓包、查找路由……3)云网故障定位工作量大:每一个微小故障的定位均需要海量的Pcap包读包分析,给运维团队带来大量的工作量。
03用户期望:1)实现在云网内任意访问的全链路追踪,消除运维工程师的逐段查找路由表、逐段抓包的工作;2)对云网流量实现全面的L3-L7层性能指标分析,能够代替人工对绝大部分的故障场景的流量性能指标进行自动化分析。
03实现价值:1)消除人工的路由追踪工作,消除人工的Pcap读包工作;2)将云原生应用故障的定界周期由数小时缩短到1分钟以内;3)将云原生基础设施的定位周期缩短到5分钟以内。
近几年,在金融同业谋求差异化、互联网平台跨界竞争的格局下,G行积极拥抱趋势并直面挑战,在数字化转型战略中一直稳步推进,是国内金融行业内数字化步伐较领先的一家企业。在2019年建设了全栈云平台,并成立了专门的云技术团队负责全栈云的选型、建设、运维。在智能运维的建设中,G行更注重于平台能力建设和科技运营数据的全面、实时和准确的治理,实现对数据中心运行情况的可观测性与运维管理的辅助决策。
01运维的日常
G行的全栈云方案选型和建设中,使用了SR-IOV、智能网卡 VxLAN Offloading、DVR 分布式路由等诸多新技术,同时使得云网络、容器网络异常复杂,但目前云管平台缺乏可观测性手段,云运维团队面临着巨大的运维压力。
这些压力体现在了日常的工作中,例如遇到云网络问题时,需要精通SDN网络的运维人员逐段查询路由,逐段抓包,逐段定位丢包、业务失败等问题,这样操作复杂,且问题定位周期长,难以发现隐性问题。
某日 zdns-business 系统在生产测试环境部署上线后,在业务同步时频繁出现响应慢、业务连接中断等问题,而且中断无规律。
运维人员立即对业务系统抓包进行分析,遇到了2个难点,一是数据包数量太大,1分钟内即抓取了5372条数据包,读包分析工作量巨大,短时间内无法快速找到故障包;二是读包分析需要懂网络协议的中级以上工程师处理,技术要求高。
业务开发、业务运维、网络运维等多位工程师进行了联合定位和读包分析,经过了6小时奋战,还是未能确定故障原因。
02云原生可观测性能做什么?
“业务响应慢、不规律中断”等问题表面看起来简单,实际上能够产生此类故障的背后原因却复杂多样,业务访问链条上的每一个物理交换机、OVS、虚拟网桥、操作系统、容器、应用等等均是潜在的怀疑对象,故障定位需要逐跳、逐段、逐次会话从不同维度进行分析,逐个排除。总体上可以梳理出以下三个大类、七个可能原因:
网络丢包问题——网络中如果存在严重丢包,将导致数据包反复的重传,影响应用交互速度,在严重情况下甚至可能造成应用交互的完全中断;
时延类问题——这里所说的时延问题也分为网络传输时延高、操作系统响应慢、应用软件响应慢三种不同的原因,其中每一种原因都可能让应用交互速度慢,甚至业务使用人员感知到中断;
异常类问题——TCP 连接建立过程、TCP数据传输过程中的异常中断、应用协议的响应异常也有可能造成业务使用人员感知到的慢和中断;
不规律中断问题的故障定位,首先需要在数千个数据包、数百个会话中精确锁定故障会话,这已经是一个非常具有挑战的工作了,更不用说对每一个会话的丢包分析、各类时延分析、各类异常行为分析,更是一个非常纷繁庞杂的事情。因此不难看出,此类问题通过人工的读包、解读、分析,需要故障定位人员具备丰富的问题定位经验,还需要投入大量的运维人力,也无法在分钟级定位问题解决问题。
DeepFlow 可观测性平台的云虚拟网络的流量指标可视化分析能力,可以完全将故障定位人员从操作复杂的逐段查找路由、逐段抓包,和枯燥无趣的海量读包中解脱出来,通过自动化的虚拟网络流量性能指标采集、自动化的流量可视化分析,运维人员可以一键绘制业务访问的全局拓扑,可以分钟内观测流量各个层次(网络层、传输层、应用层)的丰富指标(吞吐、异常、时延)
针对此类问题的三个大类、七个可能原因,G行运维人员通过 DeepFlow 在1分钟内快速勾选、调阅观测了全路径的7个指标的变化曲线,并有如下发现:
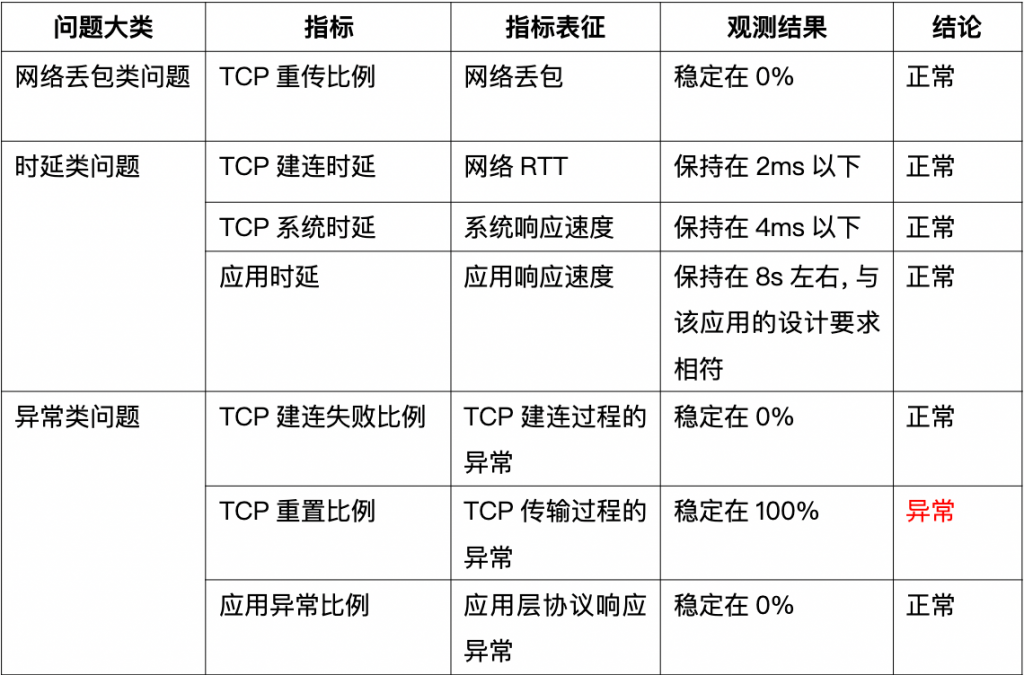
通过以上7个指标的快速观测,运维人员得出初步结论:TCP 传输过程的重置是导致此次异常的原因。
再次通过 TCP 客户端重置、TCP 服务端重置这两个指标对重置原因进行观测分析,发现所有的 TCP 传输过程的重置行为都是由服务端发起的,从而得出最终结论:服务端系统主动重置 TCP 连接,导致了业务的偶发性中断。
经业务开发人员对服务端系统的分析发现,服务端的 rabbitmq 消息队列没有及时处理,持续积压导致操作系统队列打满,触发了 TCP 连接的异常,引起了业务中断。
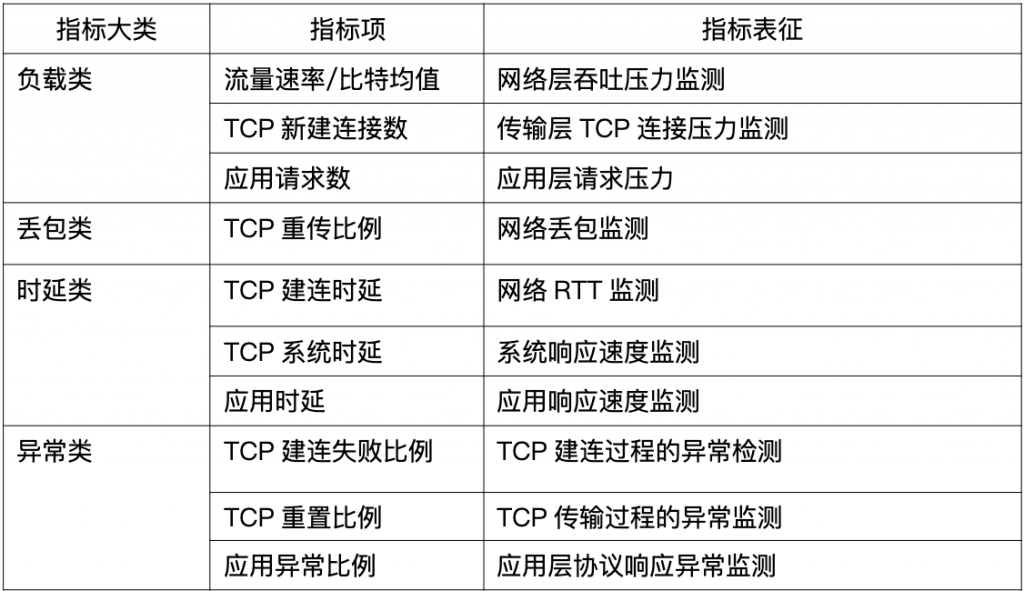
通过此次故障的定位过程,运维人员也意识到流量指标分析对云上应用运行可靠性运维保障的重要作用,因此通过 DeepFlow 的运维监控视图灵活定制能力,针对重要系统将如下十个关键指标(在上边七个指标的基础上增加三个负载类指标)纳入到日常监控运维的视图中并进行7*24小时主动监控,从而实现面向应用的更主动的监测、保障能力:
03价值
在此次的问题定位过程中 DeepFlow 可观测性平台可以完全不需要在对云网络进行逐段的查找路由、抓包、读包分析;DeepFlow 采集器自动对云网流量进行了自动化的全链路性能数据采集;DeepFlow 的分析端能够自动的将业务请求在客户端、服务端、中间关键位置进行了自动化的关联分析、拓扑绘制,运维人员无需很高的云网技术背景即可实现对云网故障的快速定位。
通过 DeepFlow 自动化的流量性能指标分析和可视化性能指标呈现,对运维问题的定位不再需要中高级网络工程师对大量 Pcap 文件分析,降低故障定位难度,提升故障定位效率,降低运维人力需求。
04展望
DeepFlow 可观测性平台通过eBPF技术实现了面向云原生应用的可观测性,通过 Skywalking、Prometheus 等开源 Agent/SDK 的数据接入,实现了云原生应用、系统、网络的全面可观测性,打通云、网、应用的数据边界。
未来,DeepFlow 会持续关注业界 eBPF 技术及开源社区发展动态,进一步拓展 eBPF 技术在其它领域的能力并挖掘更多的落地场景;继续深入推进技术研究工作,积极探索云原生可观测性最佳实践,为企业数字化运营、数字化决策等场景提供丰富、全面、客观的可观测性数据。